지난 글까지 기본적인 웹브라우저 자동화에 대한 내용이였고 이젠 엑셀과 연계하여 자동화를 구현해보겠습니다.
이번 예제는 네이버 시가총액 순위 데이터를 엑셀 데이터로 저장하는 자동화입니다.
참고로 python으로 구현하는 방법은 아래에 있습니다.
2021.05.13 - [RPA/Python] - [BeautifulSoup] 기업 시가총액 순위, 엑셀/CSV로 저장
[BeautifulSoup] 기업 시가총액 순위, 엑셀/CSV로 저장
네이버 금융 페이지 중 시가총액 순위 페이지에서 데이터를 가져와 엑셀과 CSV로 저장 import requests from bs4 import BeautifulSoup from openpyxl import Workbook import csv HEADERS = { ..
ggondae.tistory.com
방법은 크게 두가지 방법으로 구현해보려 합니다.
첫번째는 Simple Version으로 PAD가 지원하는 간단한 방법으로 구현이 가능하지만 사용자 편집이 약간 필요합니다. 다음글에 게시하게 될 두번째 방법 Detail Version은 엑셀의 편집까지 자동화로 구현하고 이를 이메일로 발송해 보겠습니다.
이번글의 목표는 시가총액 순위 100위까지의 기업 정보를 추출해 엑셀에 저장까지 진행하겠습니다.
이번 버전은 정말 간단합니다. +새 흐름으로 새로운 프로젝트를 생성하고 좌측 웹 자동화 > 새 Chrome 시작을 끌어와 URL은 https://finance.naver.com/sise/sise_market_sum.nhn 을 입력하고 최대화로 선택해 저장합니다.
시가총액 순위는 네이버에서 시가총액 순위라고 검색하면 위 URL을 확인할 수 있습니다.
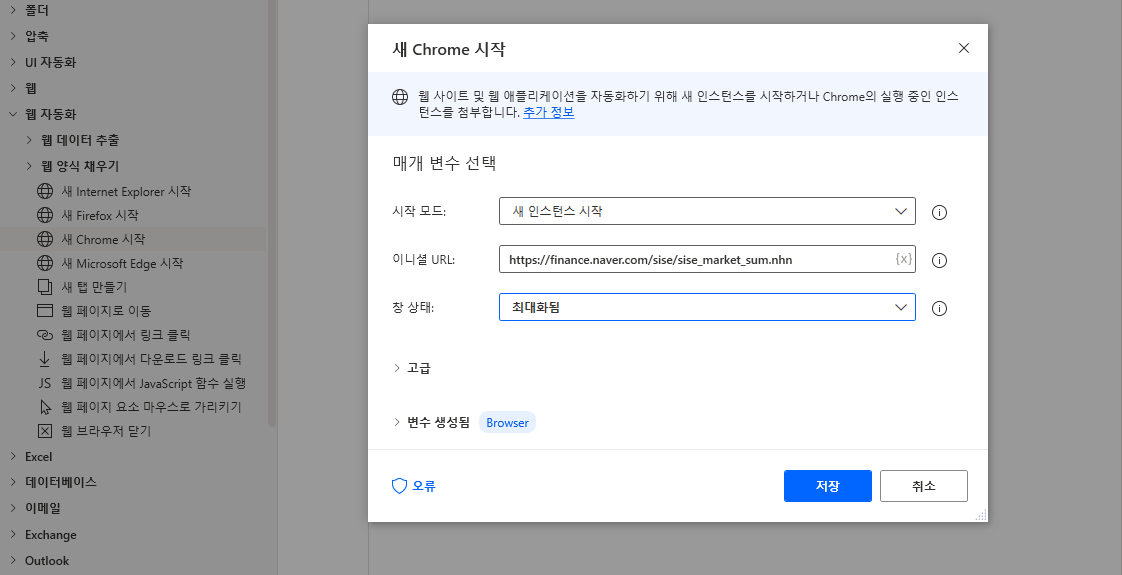
이제 상단 실행 버튼을 눌러 시가총액 순위 페이지의 구성을 살펴보겠습니다. 상단 옵션은 원하는 값을 지정할 수 있고 여기서는 단순 테스트이니 기본 표시되는 정보로 진행하겠습니다. 총 13개의 열이 있는데 그 중 맨 마지막 토론실은 의미 없으므로 추출하지 않겠습니다.
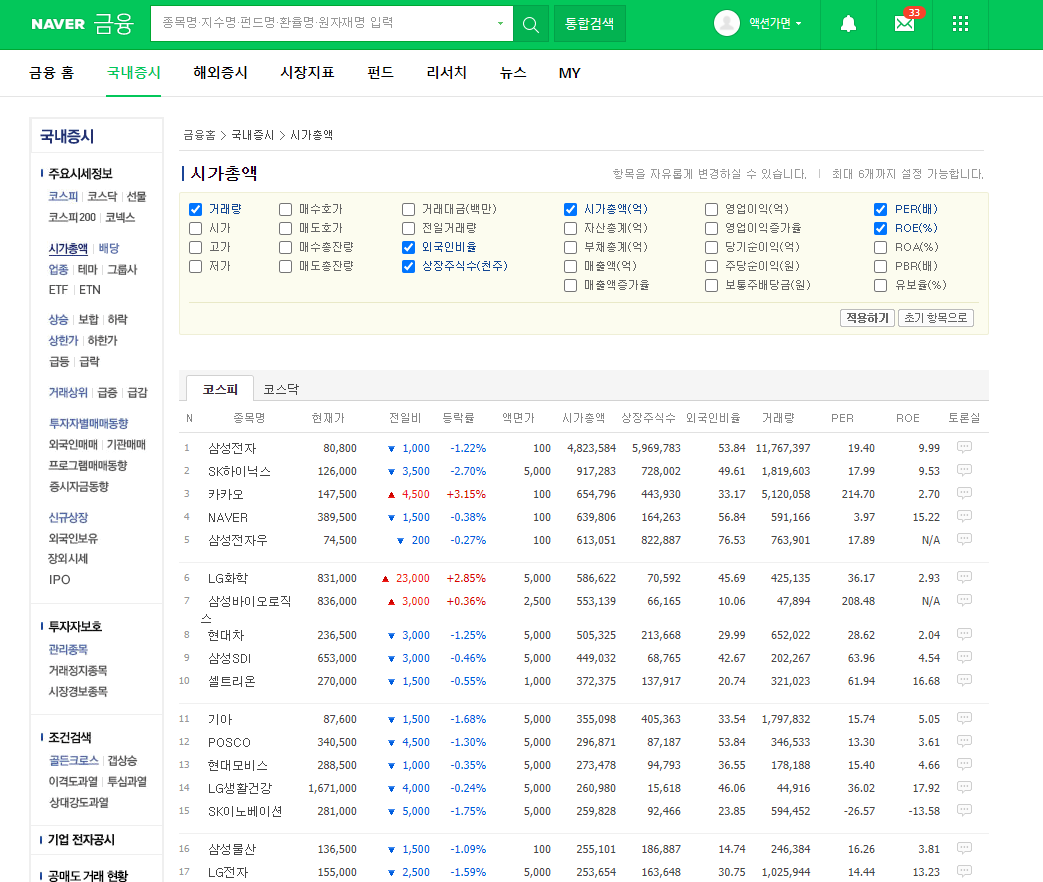
스크롤을 내려 페이지 하단을 보게되면 한 페이지에 50위까지의 기업정보만 있고 그 이후는 페이징 처리 되어 있는 것을 확인할 수 있습니다. 여기서는 100위까지 처리해야 함으로 2번 페이지를 눌러 100위까지의 데이터 처리가 필요합니다.
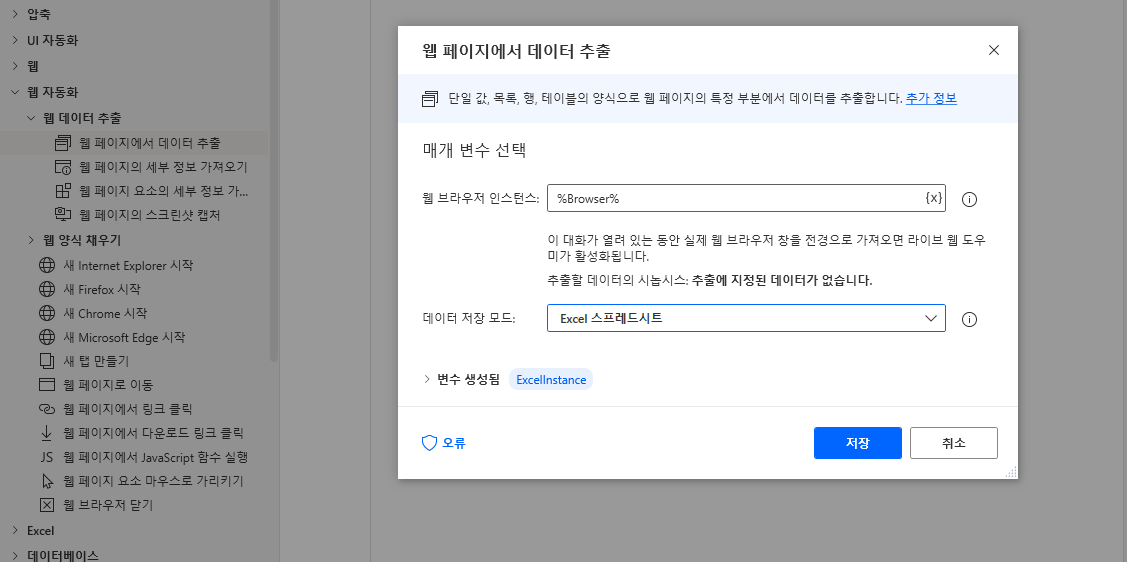
(브라우저는 닫지 마세요) 다시 작업창으로 돌아와 웹 자동화 > 웹 데이터 추출 > 웹 페이지에서 데이터 추출을 끌어와 데이터 저장 모드를 Excel 스프레드시트로 선택합니다. (저장 누르지 마세요)
먼저 데이터 추출이 끝나면 자동으로 엑셀을 실행하고 붙여넣기까지 하는 옵션이 데이터 저장 모드입니다. 변수에 넣는 옵션도 있지만 여기서는 간단한 예제이니 바로 엑셀에 넣겠습니다.
다음 중간쯤 설명을 읽어보면 "이 대화가 열려 있는 동안 실제 웹 브라우저 창을 전경으로 가져오면 라이브 웹 도우미가 활성화됩니다." 라는 문구가 있습니다. 이 이야기는 현재 상태에서 웹 브라우저로 돌아가면 추출할 데이터를 선택할 수 있다라는 뜻이고 이전에 보았던 UI요소 추출과 비슷한 형태입니다.
이제 위 웹 페이지에서 데이터 추출 창을 그대로 둔 상태에서 웹 브라우저로 돌아가면 아래와 같이 라이브 웹 도우미 창이 활성화되고 웹 페이지의 데이터가 있는 영역으로 가면 해당 요소가 붉은 색으로 하이라이트 되는 모습을 볼 수 있습니다.
이제 웹 페이지의 데이터가 있는 부분에 마우스 커서를 가져가 우측 버튼을 클릭하면 아래 그림과 같은 팝업 메뉴가 표시됩니다.
이때 메뉴 중 전체 HTML 테이블 추출을 선택합니다.
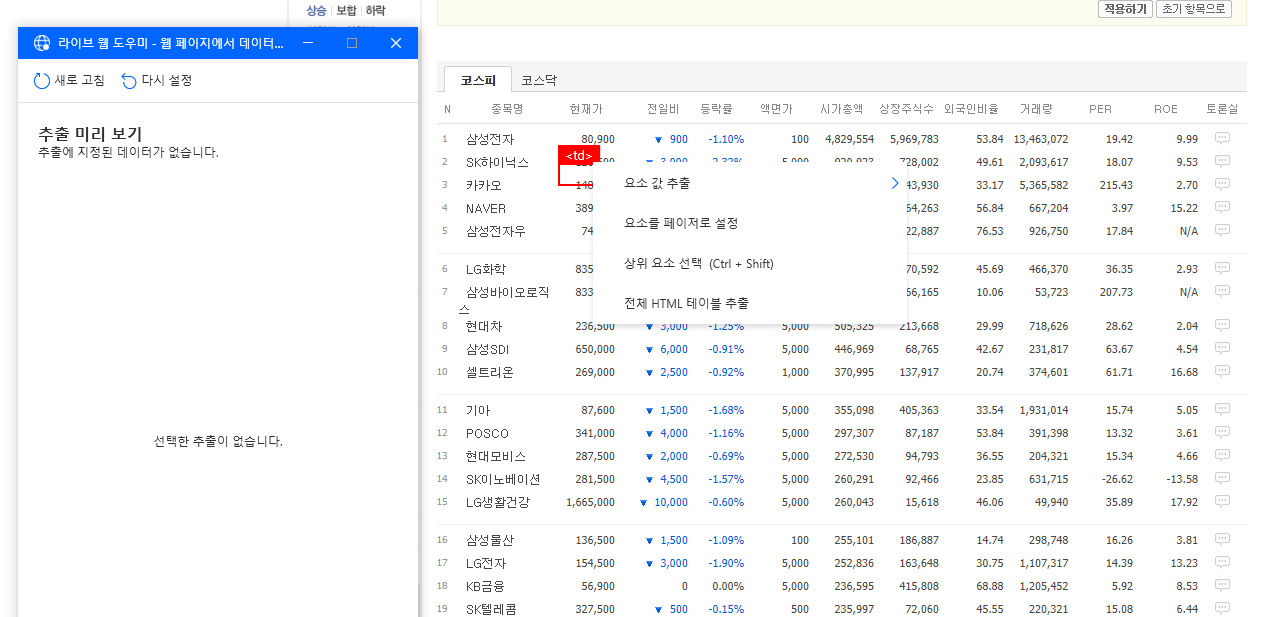
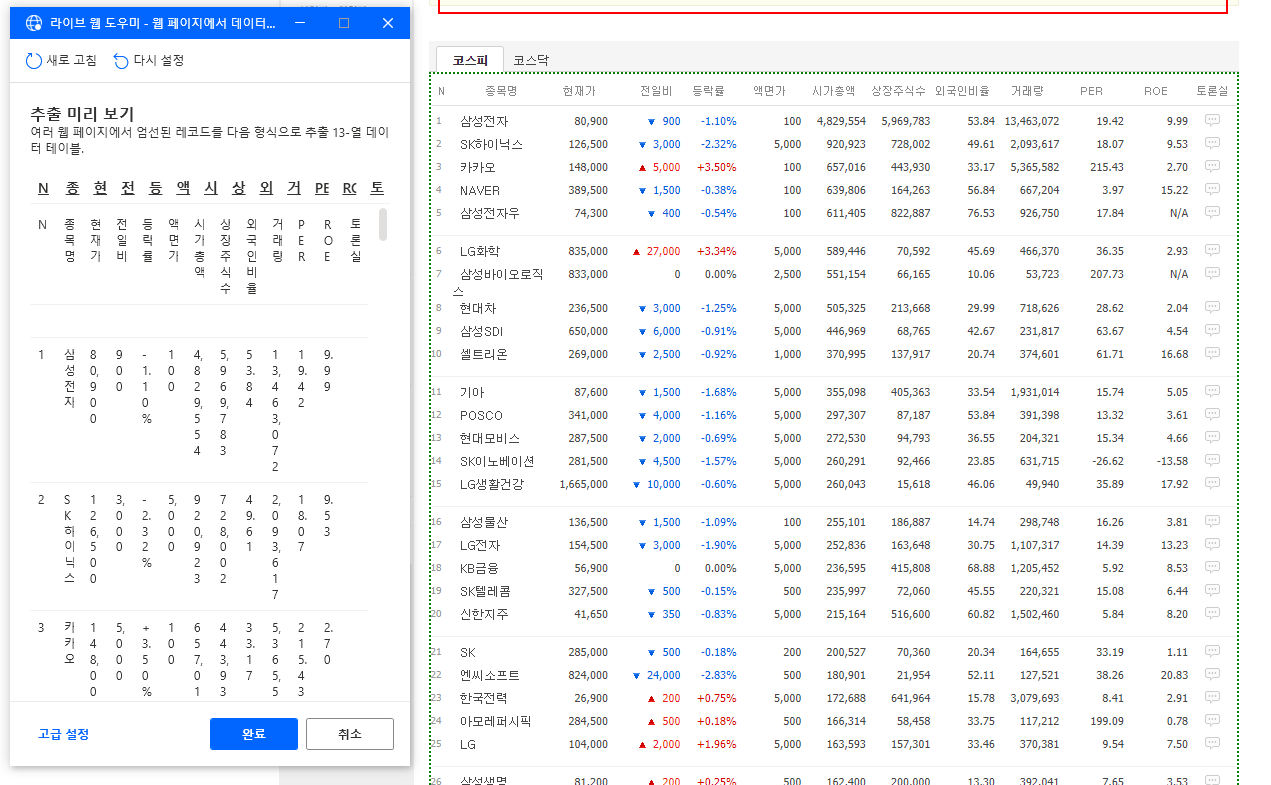
그렇게 되면 초록색 점선으로 시가총액 순위 정보가 표시된 표가 선택되고 라이브 웹 도우미 창에도 해당 데이터가 표시되는 것을 확인할 수 있습니다.
다음으로 스크롤을 내려 페이징 부분에 커서를 가져가 우측 버튼을 클릭하고 요소를 페이저로 설정을 선택합니다.

이제 라이브 웹 도우미 창에서 완료 버튼을 누르고 다시 작업창으로 돌아오면 아래와 같이 옵션이 변경되어 있습니다. 이 중 처리할 최대 웹 페이지 수가 페이징 수를 의미합니다. 해당 값을 2로 넣으면 2번째 페이지까지 데이터를 추출합니다.
"요소를 페이저로 설정"하여 처리할 "최대 웹 페이지 수"를 지정하는 것은 시가총액과 같은 pagination 형태가 아니라 예를 들면 NEXT 버튼을 클릭하여 다음 페이지로 이동하는 경우 NEXT 버튼을 "요소를 페이저로 설정" 에서 지정하고 "최대 웹 페이지 수"에서 몇 번 링크를 클릭할 지를 정의하는 내용입니다.
잘못된 부분 정정합니다.
저장을 눌러 다음 작업을 진행합니다.
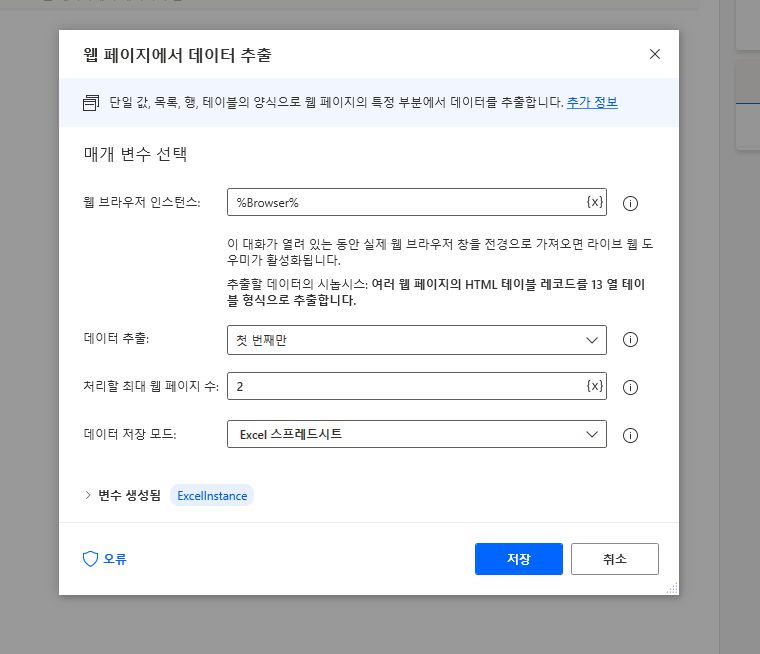
이제 추출된 데이터를 저장해야 합니다. 좌측 메뉴 Excel > Excel 닫기를 끌어와 원하는 저장 경로와 파일명을 지정한 후 저장합니다.
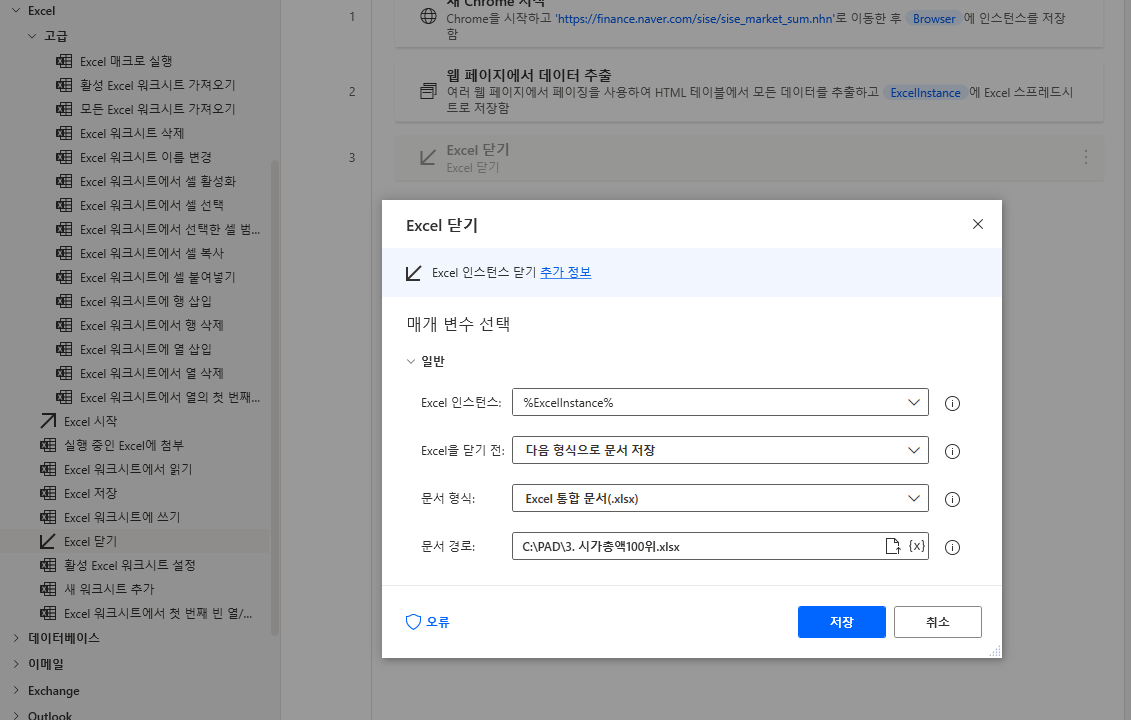
상단 실행 버튼을 클릭하여 실행하면 시가총액 순위 페이지가 2페이지까지 뜨고 엑셀이 시작됐다가 종료되는 것을 볼 수 있습니다.
이제 저장된 엑셀 데이터를 확인하겠습니다. 저장된 파일을 실행하면 아래와 같이 저장되었습니다. 그런데 좀 이상한 것들이 있습니다.
우선 타이틀이 없습니다. 분명 라이브 웹 도우미에서는 타이틀이 표시되어 있었는데 엑셀에는 없습니다.
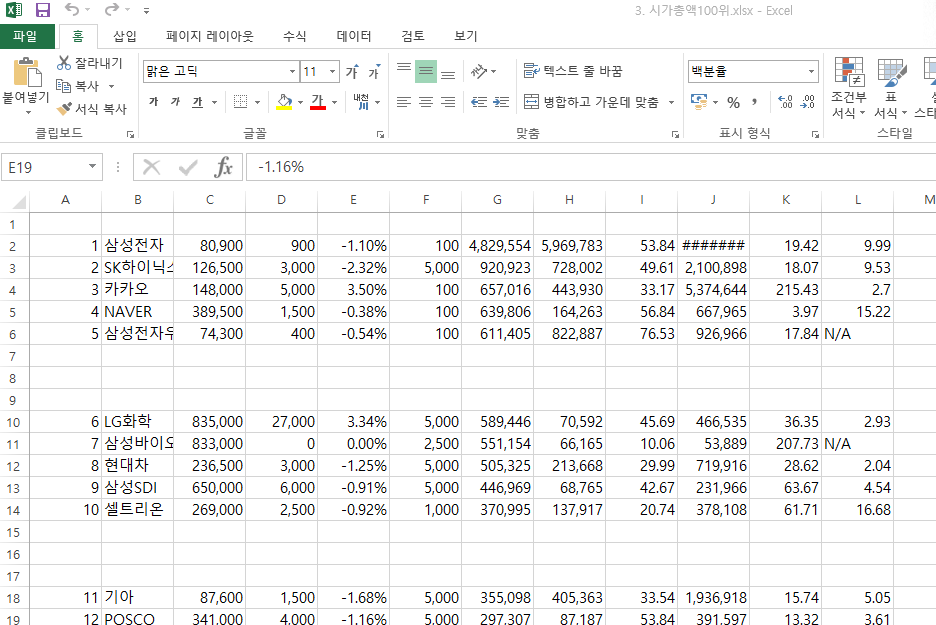
해당 이유에 대해서는 저도 원인을 잘 모르겠으나 유추해 볼만한 내용은 아마 테이블 내 구성요소가 달라 타이틀이 누락된게 아닌가 생각됩니다.
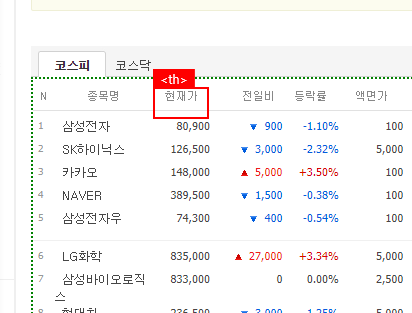
아래 그림을 보면 타이틀 부분은 <th>태그로 되어 있고 데이터 부분은 <td>태그로 구성되어 있습니다. 웹 데이터 추출이 동일 태그 기준으로 진행되어 <th>태그 부분이 누락된 것이 아닌가 생각이 됩니다.
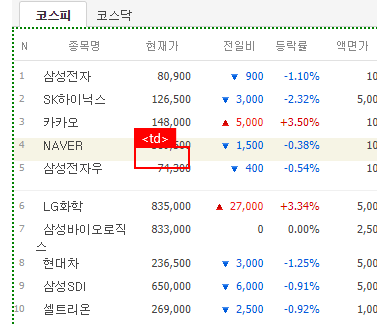
다음으로 엑셀 데이터를 보면 중간에 빈칸들이 있습니다. 위 그림에서는 5개행 기준으로 빈칸이 3번 나오는 형태가 반복됩니다. 이는 웹 페이지를 보면 5개 단위로 중간에 구분선이 들어가 있으며 해당 빈칸은 이 부분에 대한 처리로 데이터값이 없는 <td> 태그이기 때문에 빈칸으로 표시됩니다.
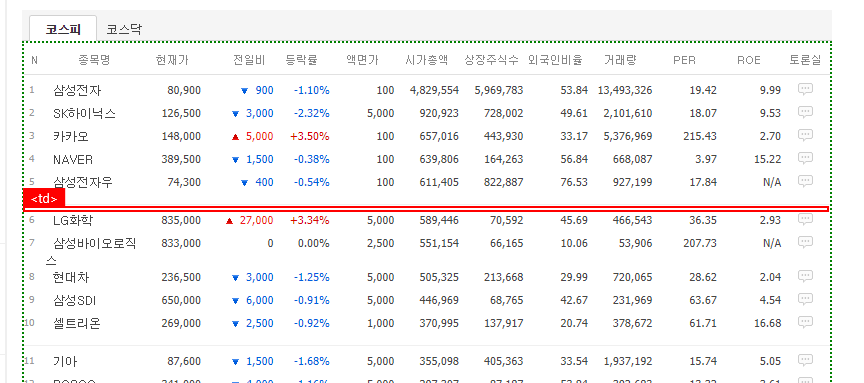
추출은 간단하게 할 수 있지만 사용자의 편집이 필요한 방법입니다. 또한 전일비의 상한가, 하한가에 대한 이미지 처리가 안되어 완전한 데이터 형태는 아닙니다.
'RPA > Power Automate Desktop' 카테고리의 다른 글
| [Power Automate Desktop] 응용 프로그램에 데이터 쓰기 (0) | 2021.06.21 |
|---|---|
| [Power Automate Desktop] 기업 시가총액 순위, 엑셀 저장 (Detail Version) (0) | 2021.06.18 |
| [Power Automate Desktop] 동적 웹 페이지 스크롤 내리기 (0) | 2021.06.17 |
| [Power Automate Desktop] 웹 브라우저 컨트롤 (0) | 2021.06.16 |
| [Power Automate Desktop] 엑셀 수정 및 새 시트 복사 (0) | 2021.06.15 |